背景
该项目源于一项指标开发需求:基于不同车辆信号完成对应指标的计算。此需求呈现出以下特性:
指标规模庞大:初始指标数量超 400 个,全年预计达 3000+ 且后续持续新增;
计算逻辑常规:主要涉及求和、最值、窗口计算等常见操作;
车型适配复杂:相同 CAN 信号在不同车型中字段名不统一,且因跨部门协作难度高,信号实体与字段名的映射关系难以预先整合,需依赖研究院与 CAN 供应商提供;
车型清单动态调整:需计算的车型存在不定期增删情况;
资源与维护矛盾突出:若将所有车型纳入单一任务并行计算,资源不足以支撑;若按车型拆分任务,又会导致后续维护成本大幅攀升。
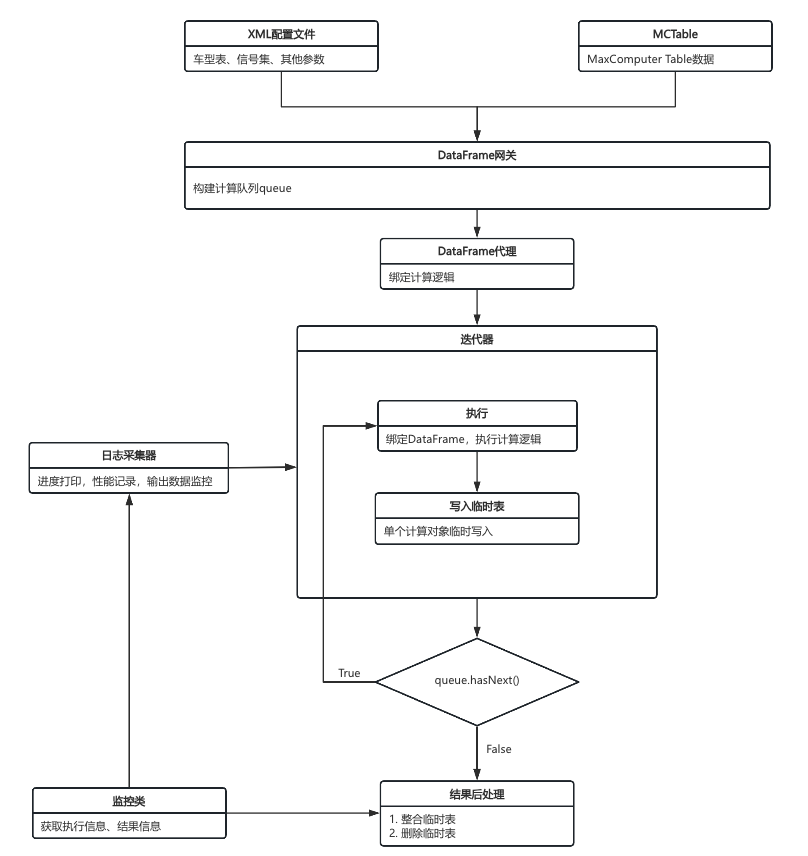
计算框架介绍
基于上述背景,我们设计了一套计算框架。
用户设置配置表,自主确定待计算的车型、信号及计算逻辑(计算逻辑已预先封装为各类算子,用户按顺序配置相应算子即可完成设置)。
框架以车型为维度循环执行计算逻辑。
后续考虑到该框架具有较高的复用价值,我们对其开展扩展开发,使其逐步发展为车联网计算平台。目前平台已构建计算协议,并形成了包括协议解析模块、表模块、计算模块、算子模块、算子优化模块以及监控模块在内的完整体系。
整体计算框架如下:
表模块
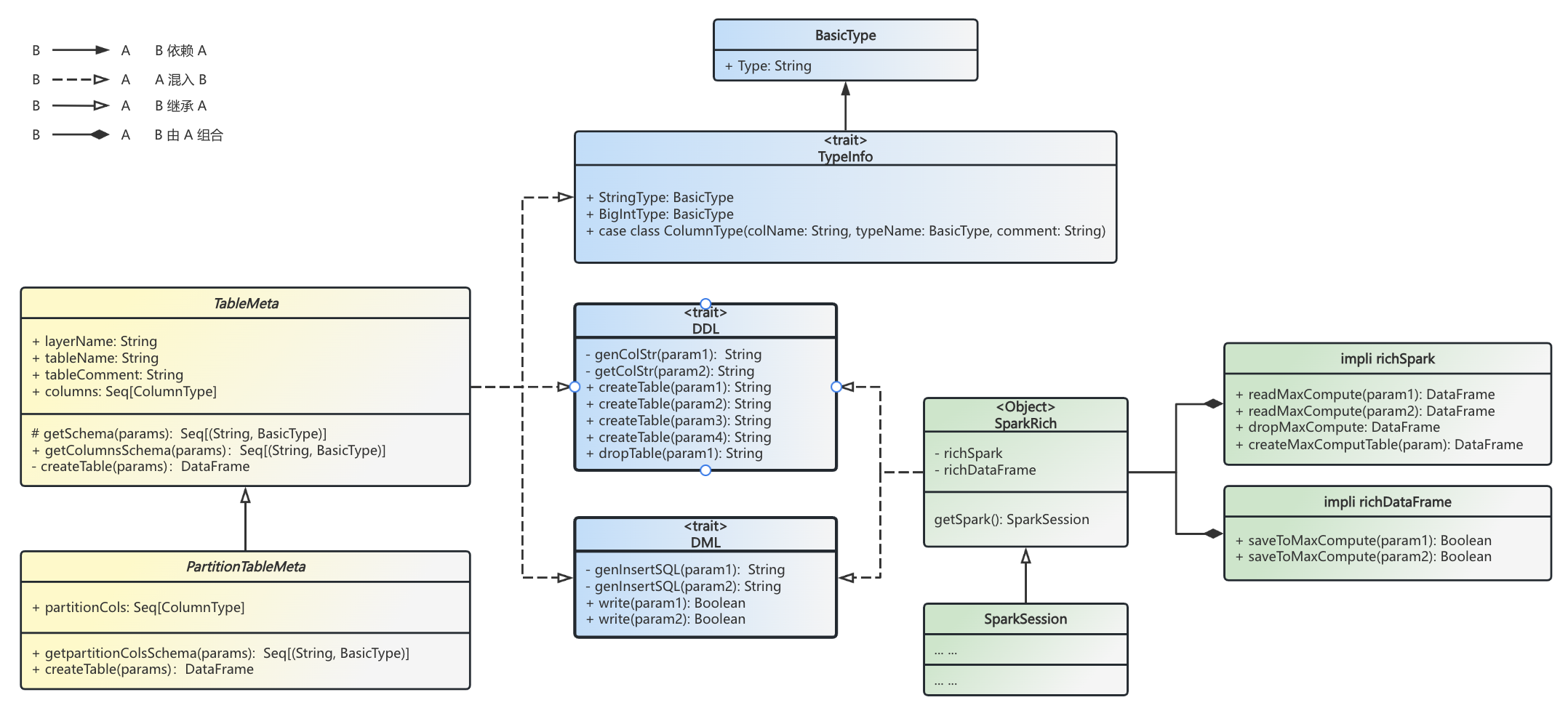
在部门平台的限制下,当使用 Java 或 Scala 进行 Spark 任务开发时,若要读取数据,只能采用 SQL 字符串的方式。例如:
val df = spark.sql("select * from df where dt = '1970-01-01'")这种字符串形式存在诸多弊端,一方面不利于从配置文件中读取数据,另一方面也给元数据管理带来了困难。为了解决这些问题,我们对 SQL 语句进行了封装。具体而言,我们通过包装 SparkSession,实现了一个 RichSparkSession。该 RichSparkSession 涵盖了表的 DDL(数据定义语言)和 DML(数据操作语言)语义。与此同时,我们按照 Op(算子)、Field(字段)、Table 的对象层次结构,构建了表模块 TableMeta。
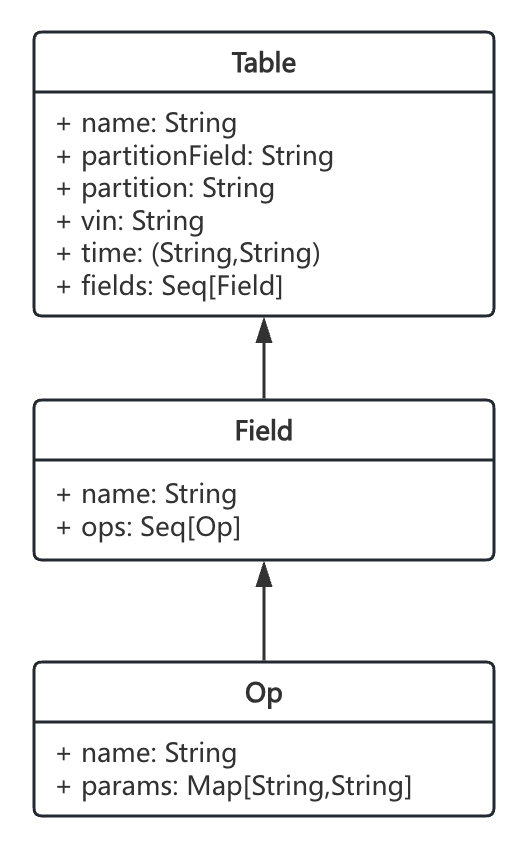
计算模块
计算模块以迭代器形式呈现,其本质为嵌套循环结构。通过配置并行参数,可以控制单次计算所涉及的 Table 数量。该模块在内部运用 union 方式达成功能,具体执行逻辑如下:

迭代器会获取 Seq[Table] 来构建第一层循环。在这一循环里,针对每个 Table,会调用 Table.getFields 方法获取 Seq[Field],以此构建第二层循环。最终,从每个 Field 中获取其所绑定的 Op,从而执行第三层的具体计算逻辑。
