一、货运司机业务全景
货运司机业务涵盖从司机招募到车辆生命周期管理的闭环。其复杂性体现在以下五大维度:
司机招募与留存
业务场景:渠道效果分析、流失预警、培训需求预测。
数据痛点:需实时监控新司机注册转化率、3 日 / 7 日留存率,识别高流失风险群体(如年龄 < 25 岁、周接单量 < 10 单的司机)。
在线运营与调度
业务场景:实时热力图、智能派单、疲劳驾驶预警。
数据痛点:需实时监控接单状态(空闲 / 忙碌)、车辆故障报警。
完单质量与客户体验
业务场景:订单完成率、客户评分分析、异常订单处理。
数据痛点:需实时关联司机行为(如绕路、超时)与客户投诉,定位服务短板。
会员体系与增值服务
业务场景:会员权益、积分兑换、精准营销。
数据痛点:需构建司机价值分层模型,实时推送个性化优惠(如订单券、收费折扣)。
车辆资产与金融服务
业务场景:车辆租赁 / 销售、保险理赔、残值评估。
数据痛点:需整合车辆行驶里程、维修记录、事故数据,实现动态定价与风险控制。
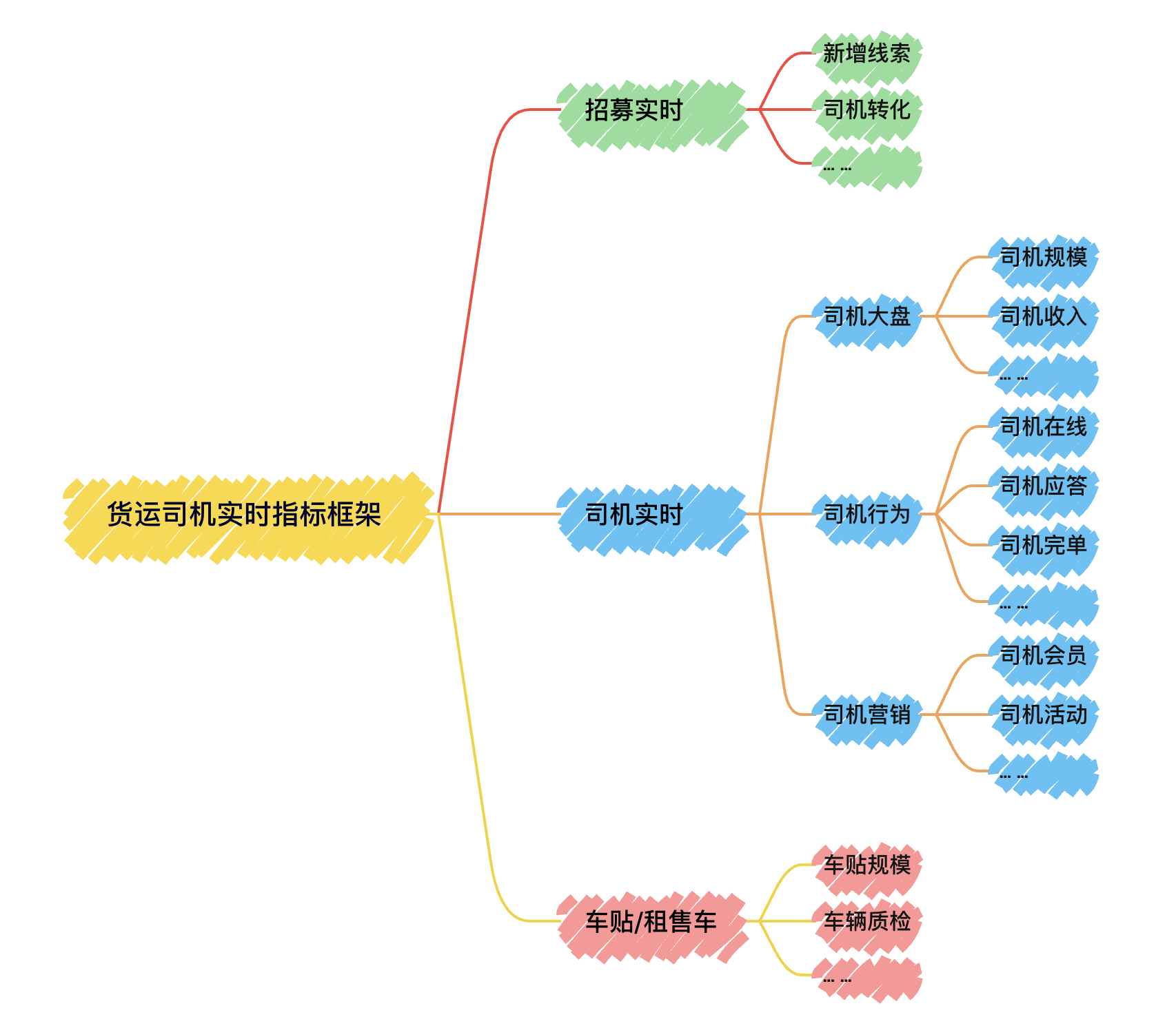
二、货运司机实时指标框架一览
我们可以通过构建3大板块的指标,以实时、量化的方式描述上述业务活动
三、实时数仓现状盘点
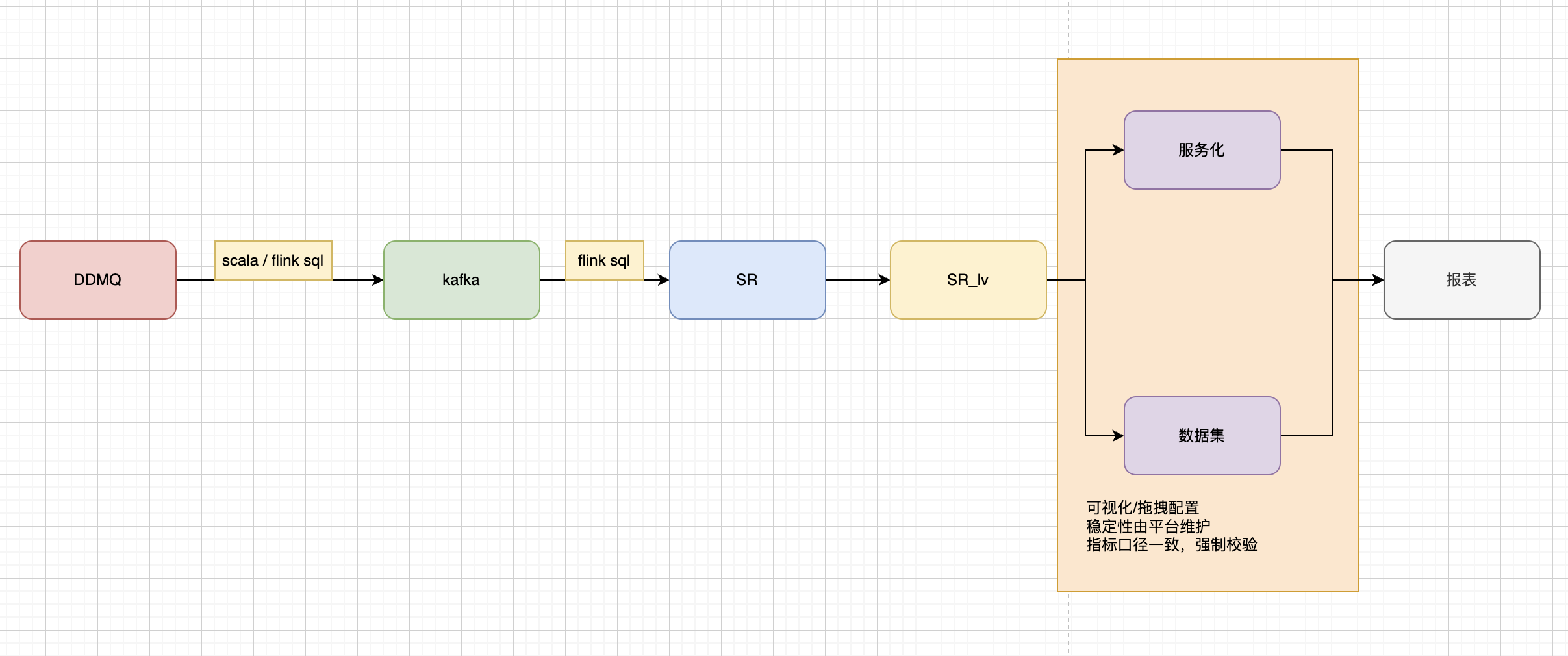
3.1 技术架构一览
数据接入与预处理
数据源:以 MQ 作为数据输入源头,承载原始数据。
初步处理:通过 Scala/Flink SQL 对 MQ 数据进行代码或 SQL 形式的清洗、转换等预处理,为后续流程做准备。
数据缓冲与流式处理
消息队列缓冲:预处理后的数据写入 Kafka,利用消息队列特性实现数据的异步缓冲、流量削峰,保障数据传输稳定性。
流式计算处理:再次通过 Flink SQL 对 Kafka 中的数据进行实时计算(如聚合、关联),完成数据的深度加工。
数据存储与分层
基础存储:处理后的数据输出至 StarRocks,进行基础存储。
接口封装:对于通用逻辑,使用SR的视图作为标准接口,统一输出口径,实现数据的分层管理,便于后续不同场景调用。
数据服务化与应用
平台处理:
服务化/数据集:基于 SR视图 构建标准的业务数据集或模型,支持业务的可视化指标配置。
平台保障:强调平台对数据稳定性的维护,确保指标口径一致,并通过强制校验避免数据不一致问题。
最终应用:服务化模型与数据集共同支撑 报表 生成,为业务提供可视化分析结果,辅助决策。
3.2 实时数仓链路
当前的实时链路单日flink成本在千元级别,共计370+个节点,其中:
MQ数据源:11个
kafka节点:40+
SR节点:90+
实时数据集/模型:130+
报表页面:90+
核心流量主要来自心跳数据,每秒数据千级别,峰值接近万级;延迟控制在百毫秒级,极端场景下达秒级。
3.2.1 实时链路图
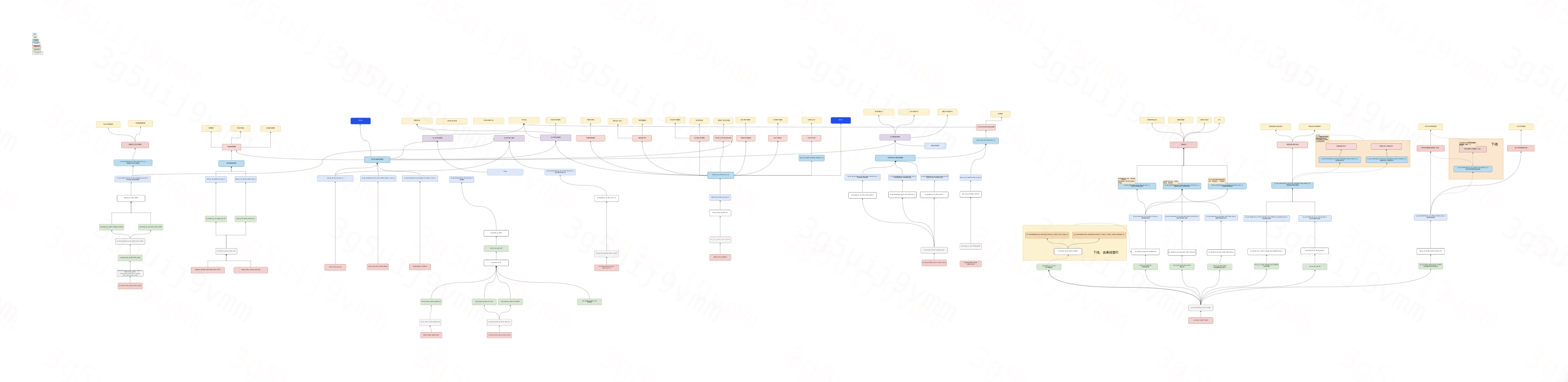
-dsdx.png)
货运司机实时链路大致可划分为5个板块,分别对应了上述业务的划分:司机招募、在线调度、完单监控、会员运营和车辆资产管理
3.2.2 存在的问题
数据源同步策略存在标准化不足问题。当前同步机制同时支持表级同步与整库同步两种模式,其中一些轻量级表级同步采用 Scala 代码实现导致运维复杂度增加,而整库同步因缺乏统一管理规范,造成存储资源浪费及运维成本上升;
主题耦合。在线、交易、司机身份主题耦合、招募与司机运营主体耦合,未进行拆分,导致提早形成宽表,下游延迟波动较大。
主次链路耦合。重保链路与此要链路未做隔离。
前置流关联操作前置引发架构层面问题。流关联的前置导致实时宽表的提前生成,由此与大量下游节点耦合,链路延迟增加,链路断裂风险提升,单节点故障扩散范围增大。
kafka / SR 节点存在冗余配置。部分通用数据处理逻辑被独立封装为共享服务后,下游消费场景发生变更,导致部分 Kafka/SR 节点仅通向另一个Kafka/SR 节点,或未被任何下游消费,造成集群存储资源闲置;
SR 视图存在冗余建设问题。视图创建缺乏统一管理规范,导致视图治理复杂度显著提升;部分视图包含复杂关联逻辑,引发下游查询性能下降;相同业务逻辑分散在多个视图中,未有效收敛,增加问题追溯难度;
实时维度写入 HBase ,导致数据处理链路层级增加。下游计算节点需额外增加 HBase 数据读取逻辑,原相对独立的数据处理链路与其他链路形成强耦合,增加了潜在延迟、破线了风险。
四、实时链路重构方案
针对现存问题,给出以下重构方案:
单表同步使用平台工具,剥离运维成本;整库同步建立库表准入机制;
对无业务处理逻辑的Kafka/SR节点进行下线,利用平台工具,MQ直通SR;
合并SR视图,将独有逻辑下沉至数据集和模型;
经业务调研,实时维度的诉求并不高,使用离线维度替代;
关联逻辑进行下沉拆分,保持链路相对独立。
五、实施结果
该方案实施历时半年,结果如下:
Kafka节点 40+ 至 20+,下线约50%
SR节点 90+ 至 40+,下线约50%
实时数据集 130+ 至 40+,下线约70%
整体延迟波动下降约10%
链路整体延迟告警减少30%,破线告警减少约60%
总体实时链路成本降低约15%