
一、业务背景
在电动汽车领域,电池的安全性和性能直接关系到车辆的整体表现和用户的使用体验。电池电芯温度是影响电池性能和寿命的关键因素之一,过高或过低的温度可能导致电池容量下降、充放电效率降低,甚至引发安全事故。因此,监测和分析电池电芯温度,及时发现温度异常情况并进行预警,对于保障电动汽车的安全运行至关重要。在电动汽车领域,电池的安全性和性能直接关系到车辆的整体表现和用户的使用体验。电池电芯温度是影响电池性能和寿命的关键因素之一,过高或过低的温度可能导致电池容量下降、充放电效率降低,甚至引发安全事故。因此,监测和分析电池电芯温度,及时发现温度异常情况并进行预警,对于保障电动汽车的安全运行至关重要。
由于电池组内各电芯的温度分布不均(如中心区域散热困难、老化电芯温升更快),由于电池组内各电芯的温度分布不均(如中心区域散热困难、老化电芯温升更快),赋权赋权能够通过差异化权重分配,精准识别高风险电芯并优化热管理策略,从而提升安全性、延长电池寿命。常见的赋权方法包括:能够通过差异化权重分配,精准识别高风险电芯并优化热管理策略,从而提升安全性、延长电池寿命。常见的赋权方法包括:
主观赋权法(如专家经验法),依赖人工经验但易受主观性影响;
层次分析法(AHP),需构建判断矩阵,计算复杂且依赖一致性检验;
主成分分析法(PCA),通过降维提取关键指标,但对数据分布敏感。
相比之下,相比之下,熵权法熵权法作为一种客观赋权方法,基于数据自身的信息熵反映指标变异程度,具有以下优势:作为一种客观赋权方法,基于数据自身的信息熵反映指标变异程度,具有以下优势:
客观性强:完全依赖数据分布,避免人为干扰;
适用性广:可处理多维度、非线性关系的复杂数据;
计算高效:通过矩阵化运算实现快速权重求解。
1.1 熵权法的计算公式
设原始温度数据矩阵为 设原始温度数据矩阵为 X=[x_{ij}]_{n*m},其中 ,其中 n 为样本数(电芯数量), 为样本数(电芯数量), m 为指标数(温度)。计算步骤如下: 为指标数(温度)。计算步骤如下:
数据标准化(极差法):
确定权重将原始数据矩阵进行标准化处理,消除量纲影响,转化为无量纲的[0,1]区间值。
x^{'}_{ij}=[\frac{x_{ij}−min(x_{:j})}{max(x_{:j})−min(x_{:j})}]_{n*m}
max(x_{:j}) 和 min(x_{:j}):第 j 列指标的最小值和最大值。
x^{'}_{ij}:标准化后的值,反映样本 i在指标 j 上的相对位置。
计算概率矩阵(归一化)
将标准化后的数据按列归一化,得到每个样本在各指标上的占比。
p_{ij}=\frac{x_{ij}^{'}}{\sum_{i = 1}^{n}x_{ij}^{'}}
p_{ij}:样本 i 在指标 j 上的概率值,满足 \sum_{i=1}^{n}{p_{ij}}=1。
计算信息熵
e_{j}=-\frac{1}{\ln{n}}\sum_{i = 1}^{n}p_{ij}\ln{p}
e_j:第 j 个指标的信息熵,取值范围 [0,1];
\ln{n}:归一化系数,确保 e_j≤1;
当所有 p_{ij}相等时, e_j=1,此时指标无区分度,权重为0
确定权重
根据信息熵计算各指标的权重,熵值越小,权重越高。
w_{j}=\frac{1−e_{j}}{\sum_{k = 1}^{m}(1−e_{k})}
w_{j}:第: j 个指标的权重,满足 个指标的权重,满足 \sum_{k=1}^{m}{w_j}=1
1.2 矩阵化计算流程
输入数据矩阵:
X = \begin{bmatrix} x_{11} & x_{12} & \cdots & x_{1m}\\ x_{21} & x_{22} & \cdots & x_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ x_{n1} & x_{n2} & \cdots & x_{nm} \end{bmatrix}
标准化后的矩阵:$$
X^{'} = \begin{bmatrix} x^{'}_{11} & x^{'}_{12} & \cdots & x^{'}_{1m}\\ x^{'}_{21} & x^{'}_{22} & \cdots & x^{'}_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ x^{'}_{n1} & x^{'}_{n2} & \cdots & x^{'}_{nm} \end{bmatrix}
概率矩阵
P = \begin{bmatrix} p_{11} & p_{12} & \cdots & p_{1m}\\ p_{21} & p_{22} & \cdots & p_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ p_{n1} & p_{n2} & \cdots & p_{nm} \end{bmatrix}
信息熵向量
E = \begin{bmatrix} e_{1} & e_{2} & \cdots & e_{m} \end{bmatrix}
权重向量
W = \begin{bmatrix} w_{1} & w_{2} & \cdots & w_{m} \end{bmatrix}
二、Spark实现
在工程实现上,选择充电结束前 5 分钟的电芯温度数据进行熵权法计算,主要基于以下考量:该时段电池内部的电化学极化和欧姆极化效应趋于稳定,温度数据受充电电流动态变化的干扰显著降低。相较于充电过程中的其他阶段,此区间的温度波动幅度最小,能够准确表征电池在满充状态下的稳态热特性,从而有效提升熵权法对温度指标权重分配的工程计算精度。
2.1 计算流程
数据预处理:获取充电结束前5分钟的充电数据
计算熵权值
使用熵权值计算电芯温度最终指标
2.2 熵权计算代码实现
熵权法Spark的实现核心是如何将矩阵计算映射到DataFrame中,首先给出DataFrame的充电数据结构:

对于DataFrame,同一vin第 i时刻数据帧代表数据矩阵的第 i个样本,其温度数组元素 j 代表了数据矩阵中的指标 j:

在极差标准化计算中,需要计算电芯温度 j在整个样本中的极大极小值。由于Spark版本为2.4,无法使用3.0版本的内置高阶函数,所以使用UDAF自定义聚合函数,求解指定窗口内的数组各元素最大、最小和求和值。三个UDAF写法类似,现给出求最小值,以做示例:
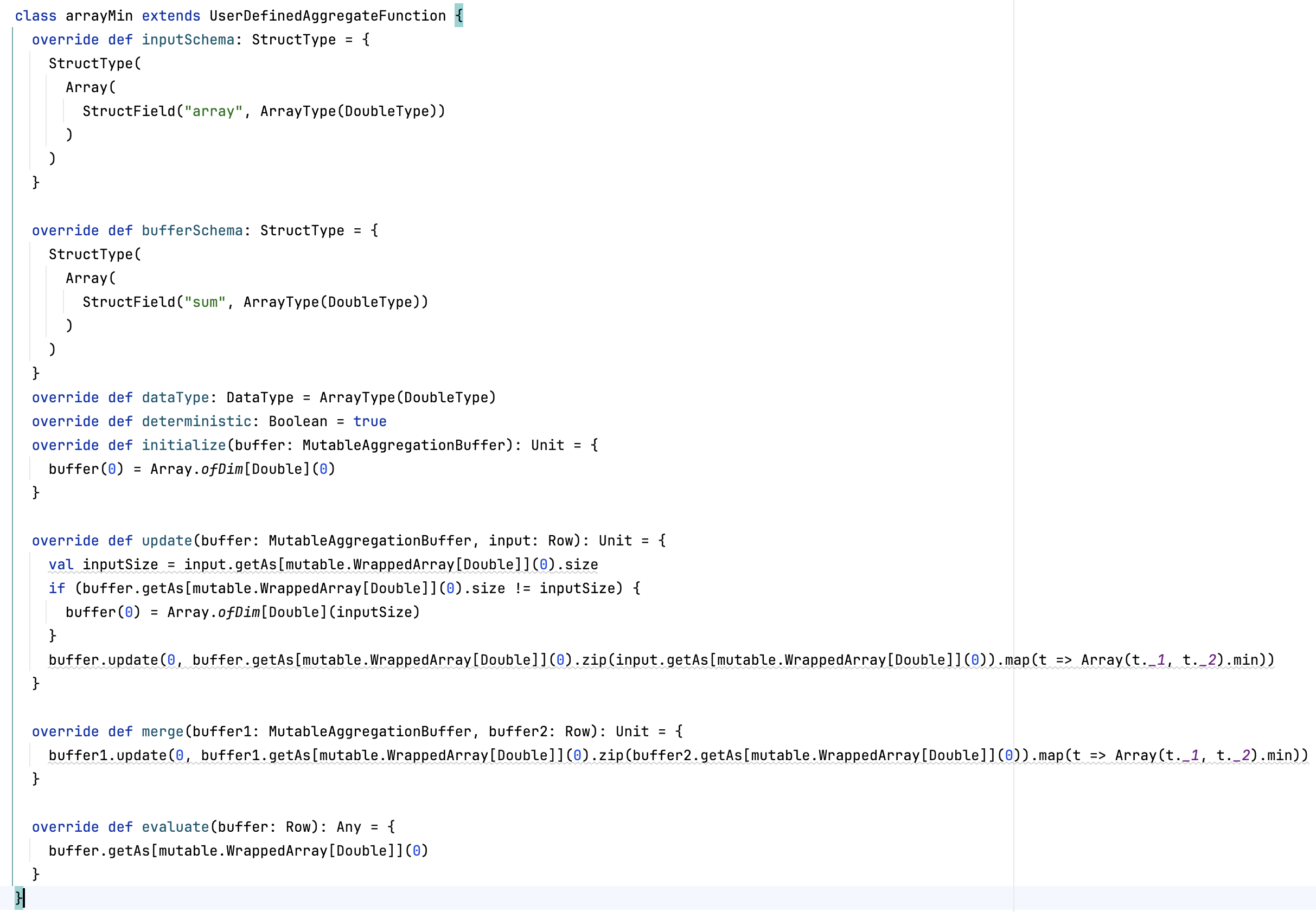
极差标准化算法实现如下,需注意0值处理:
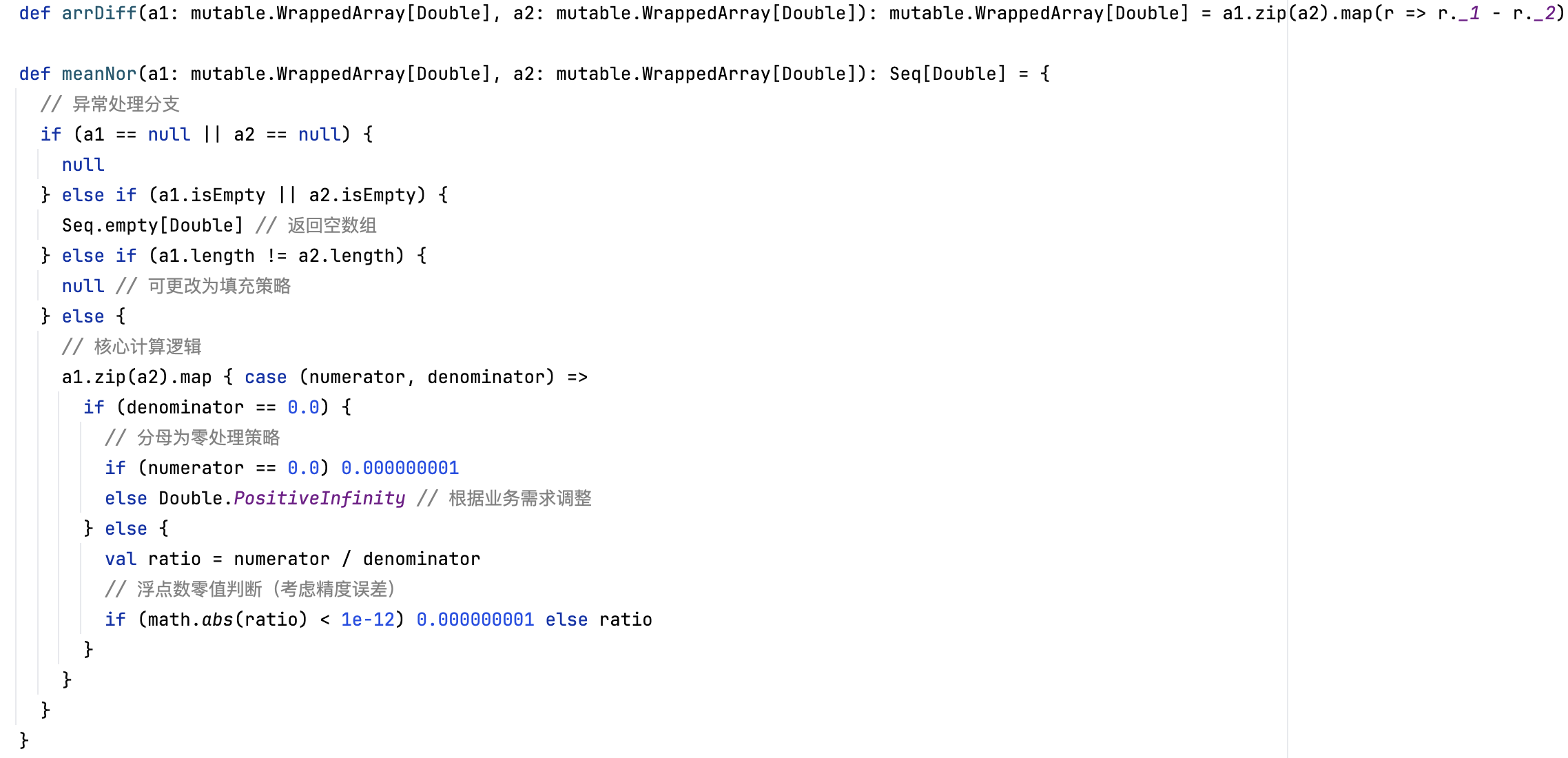
Spark标准化计算流程如下

熵值算法实现如下:

Spark熵权计算流程如下:

总结
本文针对电动汽车电池组电芯温度分布不均的问题,基于Spark实现了熵权法的热风险量化分析方案。通过极差标准化处理原始温度数据,利用信息熵客观计算各电芯温度指标的权重,有效识别高风险电芯。结合 Spark 大数据平台实现矩阵化并行计算,重点优化了充电结束前 5 分钟稳态温度数据的处理流程,解决了传统主观赋权方法的局限性。
